

As part of the VietAI Summit 2019, Dr. Thang Luong gave a presentation about the advances in semi-supervised learning, and how to train AI with little labeled data.
Advances in Semi-Supervised Learning - How to Train AI with Little Labeled Data presentation with Dr. Thang Luong, Research Scientist, Google Brain
Abstract: Despite much success, deep learning generally does not perform well with small labeled training sets. Making use of unlabeled data to improve deep learning has been an important research direction, among which semi-supervised learning is one of the most promising methods. In this talk, Dr. Luong will present Unsupervised Data Augmentation (UDA), our recent semi-supervised learning technique that works well on both language and vision tasks. With UDA, we obtain state-of-the-art performances with only one or two orders of magnitudes less labeled data.
In this talk, Dr. Luong begins by explaining basic supervised machine learning. In machine learning, a basic function of computer vision is to utilize image classification to recognize and label image data. Supervised learning always requires an input and label to correlate to the input. In doing so, you teach the AI to recognize what an image is, whether it be an object, human, animal, and so on. Dr. Luong goes on to further explain what neural networks are, and how they are used for deep learning. These networks are designed to mimic the functionality of the human brain and allow AI to learn and problem solve on its own.

These networks allow the AI to receive input, and utilize the neural network to create a final output based on the data-set the machine learning algorithm trained with.
One of the challenges when using deep learning in real-world situations is that there is often a very small amount of labeled data for the AI to work with. In these real-world situations, human intervention is required, as they must look at the data and images to annotate it for the machine learning algorithms to properly process the data. This is very costly, and requires a large amount of resources to accomplish. To circumvent this problem, a new strategy was needed.
Through this challenge, researchers discovered that when there is a lower amount of available labeled data, a hybrid approach to supervised learning is more efficient and has better results. “Semi-supervised learning” has been used in recent times to overcome this challenge, and in some cases, can provide significant benefits over supervised learning. Dr. Luong calls this the “semi-supervised learning revolution.”
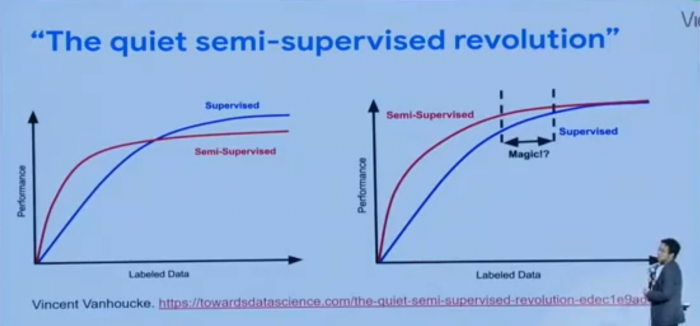
The next part of the presentation, Dr. Luong covers consistency training for semi-supervised training. This strategy allows researchers to test their algorithm to ensure consistency of their model to ensure that if there is noise and/or variation in their input data, that the model still outputs the same result. By modifying the input (labeled data) slightly, you allow the model to become more robust due to the input changes. How this is achieved is they slightly modify the original input data (an image) with slight variations to the image. This can mean changing the exposure, brightness, or even rotating the image entirely. When successful, the training model will predict the same result for all of the variations. By using this semi-supervised training method, the neural networks have the ability to propogate the label from labeled data into unlabeled examples so that the model learns to connect certain images together, and thus reducing the need for costly human intervention to label the entirety of the data.
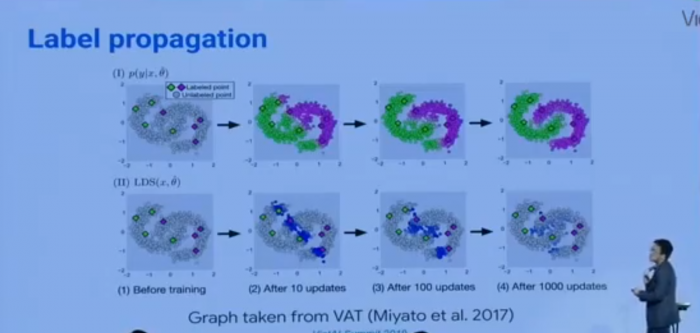
In order to achieve the goal of creating a more robust training model, Dr. Luong has employed a slightly different approach to semi-supervised training. Rather than modify the input image using traditional means, he covers what is called UDA (unlabeled data augmentation). UDA applies SOTA data augmentation to unlabeled data to improve semi-supervised learning. He gave two examples of this using language and images.
Language augmentation can be achieved by translating a statement from one language to another, and then translating that statement back into the original language. This should result in a slightly different input (a new sentence) with the same meaning.

For vision, they run a technical random augmentation, where it tries different ways of changing your input, creating variations in unlabeled image data. This technique can utilize image cropping, rotating the image, zooming in on the image, or add different colors. This allows a single unlabeled image to be slightly modified into a large amount of unlabeled data, and the model will learn to make similar predictions for all of them.

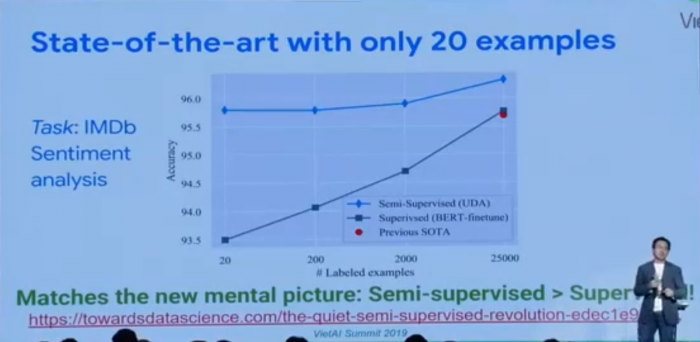
The result of utilizing UDA for semi-supervised learning for language experiments has been astounding! With just 20 examples, the model was able to exceed the performance of similar models with thousands of examples using standard supervised learning, making this method far superior than traditional methods. Additionally, for vision experiments, the UDA method was able to outperform supervised learning by approximately 30%.
Dr. Luong believes it’s important for us to consider the transition from big data into small data, and will have strong implications across industries such as manufacturing and healthcare. As semi-supervised learning continues to develop, we should continue to see additional benefits from this state-of-the-art augmentation method. For the full presentation, we encourage you watch the entire presentation, which can be found below.
To access all of Dr. Luong’s slides for this presentation, head over to Kambria’s Resource Library. The Resource Library can be accessed for free by community members who own KAT tokens. Simply register for the Kambria platform by clicking “Login/Register” in the top right-hand side of the screen. Then choose “Library” to access materials from the Summit.
About VietAI Summit 2019
More than 450 people attended VietAI Summit 2019, “AI for The Future,” organized by VietAI and Kambria. With a program featuring many reputable guest speakers from big tech companies such as Google Brain, Toyota Research Institute, Kambria, NVIDIA, VinAI Research, Vinbrain, Deakin University, and Vietnam National University HCMC, we received many fresh insights into the exciting state of AI research and application, not just in Vietnam, but also around the world. To receive an invitation to VietAI Summit 2020, Like the VietAI Facebook page and Like the Kambria Facebook page.







